13
2023/10
Nullmax获得近7.8亿元B轮融资,加速推进自动驾驶落地
致力于引领移动出行智变的自动驾驶科技公司Nullmax纽劢宣布获得总计约7.8亿人民币的B轮融资。本轮融资由岩山科技(深交所股票代码:002195)独家领投,老股东Stonehill Technology Limited追加投资,其他投资者跟投。 随着新一轮融资的落地,Nullmax正式驶入全新发展阶段。在充足的资金支持下,Nullmax将有序扩大团队规模,提升交付能力,满足行业客户快速增长的智驾量产需求;并深化和扩大产品技术研发,巩固机器学习、视觉感知等核心技术优势,为新产品、新业务、新市场的开发和落地提供关键的技术支撑。 在本轮融资及相关交易完成后,Nullmax将成为岩山科技合并报表范围内的控股子公司。Nullmax将通过来自岩山科技的资源整合与协同,加速自身发展,巩固各项优势,扩大商业化规模,践行打造全场景无人驾驶应用,加速移动出行智变的品牌使命。 Nullmax一直专注于打造面向大规模量产的自动驾驶应用,并在业内率先推出了行车、泊车一体化的智能驾驶系统解决方案。从2021年一季度开始,Nullmax先后获得了基于TDA4芯片平台的行泊一体、视觉感知量产项目定点,以及基于Orin芯片平台的行泊一体量产项目定点,开启产品技术的商业化、规划化落地。 目前,Nullmax拥有MaxDrive卓行和MaxVision远见两大产品线,可以为客户提供完整的智能驾驶系统和定制化的视觉感知模块。依托于平台化的技术架构,Nullmax的产品既能通过高中低的不同配置满足差异化的量产需求,也能以更高的效率和更低的成本为客户交付功能完善、性能优异的智能驾驶系统。 同时,Nullmax与多家知名汽车厂商和一级供应商建立了面向量产的深度合作,先后获得多家行业客户的定点量产项目,合作伙伴包括上汽、奇瑞、江铃等知名汽车制造商。 现阶段,Nullmax正在有序推进各项量产项目的交付工作,推动高竞争力新量产方案的上车,以及Ultimate Self-Driving(终极自动驾驶)等高阶功能的落地。进入新的阶段,Nullmax将持续深耕智能驾驶领域,并推动自动驾驶业务和技术快速发展。 新一轮融资之后,Nullmax将继续致力实现引领移动出行智变的品牌愿景,朝大规模无人驾驶的量产之路继续前行。
Read more

11
2023/01
新成员报道 | 有点“牛”,爱了AI了!
Read more
-
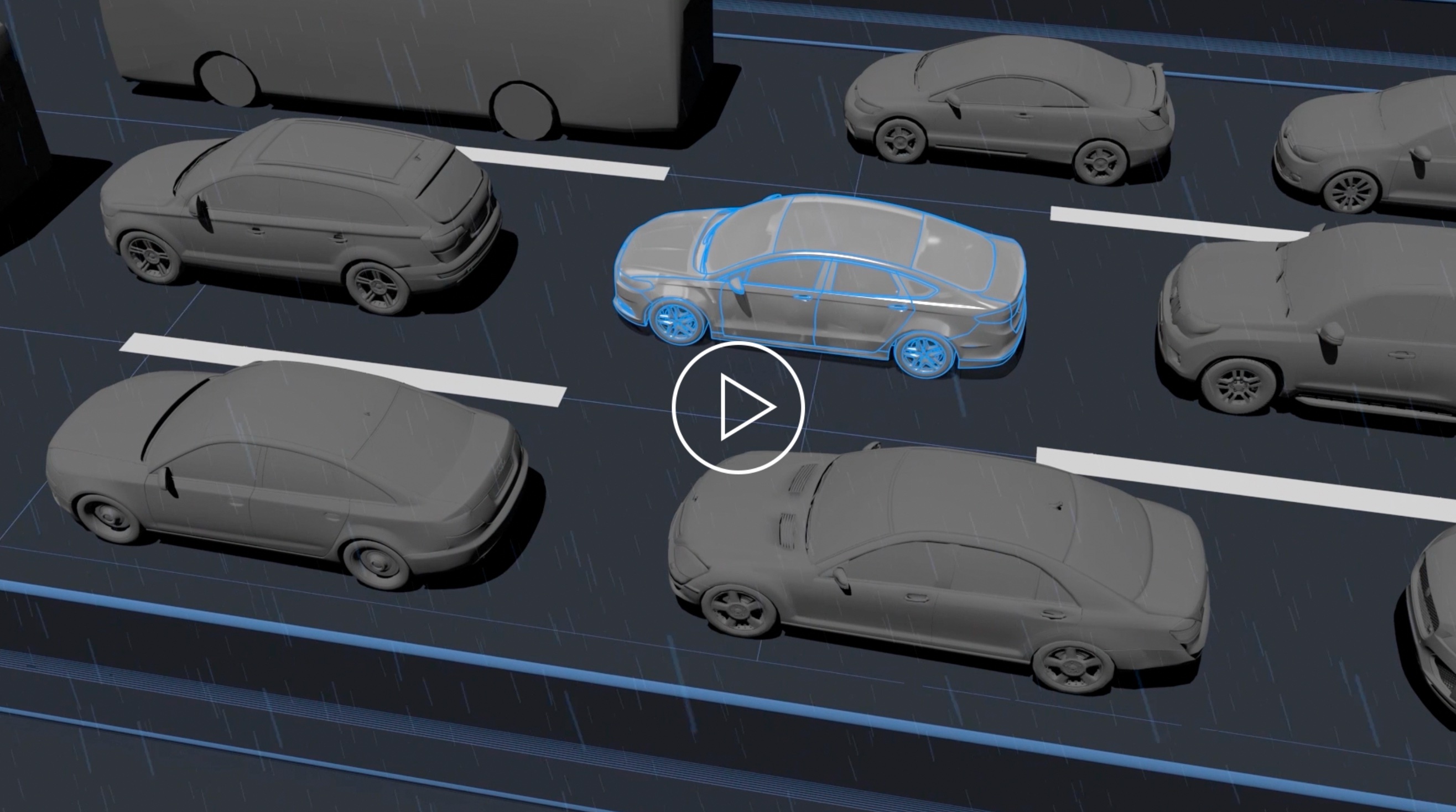
泊车不断在升级,以后停车so easy对于开车出行的人来说,停车难和堵车苦一样,是一个永远都无法避开的话题。虽然这些年来出现了很多的辅助性技术,但是实际的停车体验仍谈不上尽善尽美。 在很多时候,司机朋友们不得不在停车场前大排长队,或是在停车场内“刷圈”找空位,偶尔还得在“夹缝”中将车辆送进车位……路上半小时,停车20分钟,是很多人都曾有过的经历。如果再停到远一点的地方,“栉风沐雨”地取车也是难免。】= 可以说开车出行所带来的便捷,常被这样耗神费力的停车经历冲淡不少。不过,这样的日子真就没有尽头吗? 答案当然是NO。 从自动泊车说起 早在几年前,不少新车就装上了一项叫做自动泊车的功能,率先向停车难问题发起了挑战。 司机将车开到空车位前面,就可以使用这项功能将车停进车位中,过程中只需要在驾驶座上简单操作几步,然后监视车辆周围环境不出问题就行。 在这个过程中,车辆主要是靠超声波雷达来感知环境,也是靠它来发现空着的停车位。当汽车低速经过停车位边上的道路时,它能探测出旁边是否有一块尺寸符合车身要求的“空地”,然后慢慢完成泊车。 但是由于技术本身的限制,自动泊车并没有将很多人从停车难的“苦痛”中解救出来。这项功能非常基础,仍需要司机把车开到空车位旁边,它的车位识别率并不高,通常只支持垂直和水平车位,不能识别划线的车位,需要有汽车、墙面等参照物,不能识别各种各样的障碍物并避障……泊车过程中司机需要持续注意车内和车外的情况,主动或被动地进行一些操作。 因为车辆仅使用超声波雷达作为环境感知的传感器,获取到的信息十分有限,所以也就只能实现基础的泊车辅助。 本质上来说,自动泊车也只是部分地解决了“倒车入库难”和“侧方停车难”,它的自动化程度并不高,远没有到达自动驾驶的地步。 视觉技术的魔力 要想汽车的泊车功能聪明得像人一样,首先要做到的就是它能像人一样可以看见和看懂周围的世界,而这背后的关键就是以计算机视觉为代表的一系列感知技术。 对于汽车来说,摄像头是极为“明亮”的眼睛,它能提供丰富的环境信息,从各不相同的颜色到千奇百怪的形状……几乎是所有泊车用得到的环境信息,而不再只是简单地探测距离。 当车辆获取到的信息越充足,它能够完成的事情也就越多了,这使得泊车功能的可用性大大提高。借助车上的摄像头,车辆不仅可以在泊车功能中应用VSLAM技术,还可以实现对各种车位的检测,可以检测车辆的通行空间,可以检测行人和车辆等障碍物并进行避障…… 过去司机所遇到的排队“进场”、苦寻空车位、停车“左支右绌”、停车位距离远等等问题,都能在这个更为先进的自主泊车功能上得到改善。 量产的自主泊车 Nullmax采用以视觉为主融合超声波雷达的低成本单车智能自主泊车方案。 在不少人看来,停车场及周围因为环境相对封闭、车速相对较低,在自动驾驶量产方面具有很大的优势,但是这并不等同于实现自主泊车的量产应用难度就不高。实际上,自动驾驶在这个特定的应用场景下也有着并不妥协的技术要求,比如定位的精度和稳定性、障碍物检测的准确率和速度,等等。 如果在室内停车,或是在高楼林立的园区穿行,车辆的卫星定位性能可能会急剧下降;泊车过程中如果遇到爬坡,车辆可能因为有仰角而无法看到障碍物;在车辆、立柱、路口较多的停车场存在不少盲区,容易突然出现近距离的障碍物……而这些只是量产中需要解决的一小部分问题,自主泊车的挑战可以说一点也不小。 实现自主泊车需要完成一系列的工作,从建图、导航、寻找车位到车辆的泊入和驶出,必须样样都经得住考验。Nullmax的泊车方案支持水平、垂直、斜向车位的自动泊车,完成精准泊入。除了常见的车位类型,它同样也能够识别砖草车位、夜间车位、模糊车位等特殊的车位,具有很高的车位检出率和检准率。 为了安全地处理各类工况,尽可能地提高泊车体验,Nullmax为车辆提供了360°全方位的感知能力。依靠配备的传感器,车辆在泊车场景下可以稳定检测50米远的行人,150米远的车辆,在巡航、泊车的过程中实现无死角的自主避障,并且做到随停随走。 而视觉和超声波融合检测可通行区域,也让车辆的感知没有盲区,定位精度可以达到厘米级。处理各种的极端情况,如PV管、垃圾桶、纸箱等未定义障碍物。对于突然出现的近距离障碍物,系统可以触发紧急制动保障安全。 除此之外,通过HMI系统也可实现包括选择车位、智能召唤、紧急制动等功能在内的智能友好的人机交互。 Nullmax的泊车方案采用视觉方法建立地图,通过视觉输入的语义信息和地图构建模块,实现高效、高精、低成本的建图。而专研的泊车导航系统,也能让决策规划的结果更可靠,结合泊车场景下多急转弯、岔路口的特点,在相应工况做出调整车速、重点关注两侧来车等针对性的决策。 在室内和室外,以及上下坡地段,Nullmax的泊车方案可以实现厘米级的定位精度,并且场景鲁棒性高,能够适应光线、天气变化等情况,消耗内存少、稳定性高。 这样一套实用易用、安全稳定、成本够低的泊车方案,能够为很多司机在平常上下班的时候提供不少方便。 融合一体化方案 事实上,自动驾驶车辆在泊车过程中,一定会遇到方方面面的难题。这些停车场有的是地下,有的是地上,有的则是多层;它们有的是直接在马路边上,有的则是在院区或者园区内;除了常见的多种车位外,还会遇到很多的非标车位。而且在路上和车位中,也随时可能遇到各种各样的障碍物。 这些方方面面的难题,都对自主泊车的性能,尤其是感知的性能,提出了很高要求。软件算法和硬件配置的不断升级,让汽车变得越来越“聪明”,并且持续进步,但与此同时在车端以外布置设备,让停车场也“聪明”起来,也是一条可选的路径。 在一些复杂的停车场景中,人车密度大,行人、普通车辆以及自动驾驶车辆混合在一起,环境复杂且变化快,单一技术存在功能失效的风险。而融合一体化的方案可以形成多传感器前融合的车载感知新系统,让场内设备与车上的感知、通讯模块融合,来实现在极端复杂泊车场景下的泊车功能,并且实现停车场间的智能化调度和停车场内车位的动态规划。 融合一体化的泊车方案可以使用车辆原有的视觉避障和自主泊车配置,对规划控制系统进行升级,增加少量新的配置,就能够将泊车的体验进一步完善。 随着自动驾驶的出现,停车难和堵车苦一样,这个存在了很久、困扰无数司机的用车难题,正在一步步得到解决。相信在以后,无论是怎样的停车场和停车位,都很难再“为难”大家!23 2020/07Blog
-
纽劢研习社 | 视觉SLAM定位二三事写在前面的话: 在纽劢科技,研发一线的工程师们会追踪自动驾驶的前沿技术,并结合开发和应用中的思考实践,定期在内部进行分享。每一次这样的交流,都是一场知识的碰撞和思路的拓展,所以我们用「纽劢研习社」将这些精彩的分享记录下来。欢迎你来这儿与我们交流和碰撞,一起擦出意想不到的知识“火花”~ 本期话题:视觉SLAM定位。内容要点: 1. Why visual localization 2. 传统视觉定位的思考 3. 非深度学习方法的应用 4. 深度学习方法的应用:Feature Points,Detection,Semantic Segmentation 01 Why Visual Localization? 高精度定位模块是自动驾驶中重要的组成部分,它的实现方法和涉及的传感器方案有很多,对应的优缺点也各不相同。而利用车载摄像头实现的视觉定位,无疑是未来不可或缺的一种。 依靠视觉进行高精度定位的方案具有如下特点: 1)满足车规、成本低廉,基于摄像头实现而不依靠昂贵传感器,更符合市场需求; 2)在卫星定位信号较差的位置仍可正常工作,例如穿行在城市高楼间或在高架下、隧道内时; 3)摄像头自身捕捉信息丰富,可以借助强大的感知能力最大化地获取车辆环境信息。 因此视觉定位作为自动驾驶中的一项核心技术,已经应用到包括自主泊车在内的多类场景中。 02 传统视觉定位的思考 早在2011年开始的欧盟项目V-Charge1,就是一项基于视觉定位的具有完整代客泊车理念的AVP项目。它基于传统的SFM框架离线构建视觉特征地图,当车辆再次来到停车场时可以通过匹配地图上的特征点,实时估计车辆位姿实现定位。 [caption id="attachment_1141" align="aligncenter" width="640"] (图1:视觉特征点地图)[/caption] 不过基于传统视觉算法研发的V-Charge,面临着这样的问题:自主泊车要求车辆具有长期定位的能力,例如能在数天乃至数月后在同一地点进行定位,但依靠单一数据集构建的特征地图很难满足要求。 V-Charge的解决方案是:用同一停车场不同时间段的数据集,构建融合成一个视觉信息更加丰富的长期有效的特征地图。但是这并不能从根本上解决长期定位的问题。 这正好引出了视觉定位面临的一些难题: 1)如何让视觉定位前端算法更加鲁棒?前端特征的选取和数据关联一直是视觉定位中的难题,相比之下后端算法已经相对成熟和稳定。 2)如何实现长期有效的定位?Long-term localization与SLAM技术本身的关注点不同,后者更关注前端特征的选取和后端理论框架的搭建,而前者更关心提升定位算法稳定性,特别是长时间跨度下的定位鲁棒性。 而要解决这两个问题,从目前的研究和应用来看,大概有以下的方向: 1)特征点的选取。使用合适的特征点算法,或使用多个数据集用于地图构建; 2)搭建更好的相机系统或者使用新颖的相机模型; 3)应用深度学习提升视觉感知能力,尤其是将视觉前端的鲁棒性做得更好。 03 非深度学习方法的应用 在这三个方向中,特征点的设计以及相机模型和相机系统,都属于非深度学习的方法。 其中,特征点的选取方面的研究开始得最早。不断有研究人员提出更鲁棒的特征点检测方法,来解决环境光线、视角变化、尺度变化对特征点检测和匹配的影响,同时利用多个图像数据集来弥补单一数据集构建地图信息不足的问题。 [caption id="attachment_1140" align="aligncenter" width="640"] (图2:多数据集地图特征点的综合与更新)[/caption] 而相机系统,指的是用多个相机构成的传感器系统。它既可以解决单目相机尺度无法估计的问题,也能提升视觉定位的鲁棒性和精度。 例如某个相机被遮挡或者面对没有纹理的墙壁时,其他相机仍能正常工作,视觉定位就不容易失效。 再就是相机模型,它主要解决传统的相机投影模型在图像处理中存在的局限性。因为传统的Pinhole模型不太适合鱼眼相机,原始图像产生的巨大畸变会影响图像特征的提取,所以有人提出了新颖的相机投影模型。 比如equirectangular projection,cube-map projection和cylinder projection。它们的初衷都是在不丢失信息的前提下尽可能减小图像的畸变。 [caption id="attachment_1139" align="aligncenter" width="480"] (图3a:不同的相机投影模型 - 投影模型示意图)[/caption] [caption id="attachment_1138" align="aligncenter" width="480"] (图3b:不同的相机投影模型 - 真实图片投影示例)[/caption] 通过在特征点的设计和选取上做努力,或者是在相机模型和相机系统上下功夫,都可以一定程度上提升视觉定位的效果。 04 深度学习方法的应用 近几年来深度学习发展迅速,因此也有研究人员将深度学习应用到视觉定位中,进行前端特征的提取。 这些应用大体分为几类: 1)基于深度学习的特征点提取和描述子计算; 2)基于目标检测的视觉定位; 3)基于语义分割的视觉定位; 4)其他的深度学习的定位算法,比如GN-net利用特征图进行位姿计算的方法,或者是其他直接用端到端方式进行定位的方法。 [caption id="attachment_1137" align="aligncenter" width="640"] (图4:基于feature points, detections, segmentations的视觉定位方法)[/caption] 深度学习在图像深层特征提取上具有优势,可以弥补传统视觉算法的不足,利用深度学习改善视觉定位算法的前端,使其鲁棒性得到提升。 Feature Points 其中最直接的想法,就是将深度学习应用在特征点提取上。前两年提出的SuperPoint2是比较典型的代表。…28 2020/09Blog
-
纽劢研习社 | 深度图的「非深度讲解」对很多人来说,自动驾驶早已不是一个陌生的名词,但是深度图(Depth Map)的话,相信不少人还是第一次听说。 顾名思义,深度图是用来反映深度信息的图像,而其中的深度信息指的就是距离信息。它用来描述相机拍摄到的场景图像中每个像素点到相机的深度,计算环境中物体到相机的距离。 [caption id="attachment_1125" align="aligncenter" width="640"] (图1:深度图示意效果。颜色越浅的部分深度越小,距离越近。)[/caption] 01 深度图的基础知识 在自动驾驶中,如果车辆能够稳定可靠地获取场景中各点的深度信息,那么它的作用是显而易见的,比如进行像素级的测距,3D目标检测,未定义障碍物的检测,等等。从而可以实现路面上所有突出障碍物的检测,以及任意障碍物的测距。 另外,将相机图像结合深度信息充填RGB色彩也可以生成像素级点云,实现类似于激光点云的效果。虽然它的测距准确性不及激光雷达,但点云远比后者稠密,而且RGB着色不需要人工进行同步、校准等工作。 [caption id="attachment_1124" align="aligncenter" width="640"] (图2:视觉方法生成的像素级点云效果示意)[/caption] 可以说,深度图在自动驾驶领域有着相当广阔的应用前景。业界求深度图方法的有很多种,归纳起来可以分为三类: 1)双目相机结合立体图像,模拟人眼的立体视觉,将同一点在左右两幅图像不同位置进行匹配后,结合相机外参求得深度。 2)单目相机结合单幅图像,直接进行深度推理。将单目的照片结合单目的深度图或激光点云,放入Encoder-Decoder模型中直接进行学习。 3)单目相机结合时序图像,用前后时间图像上的点进行匹配,运用一些SLAM的假设求出相机位姿和周边环境中各点的深度。 双目方法较为常用,它将两个相机横向严格放置,预先通过标定获取焦距和基线长度,在知道某点在左右两幅图上的横向位置后便可计算出视差,然后利用相似三角形的原理求出深度。 [caption id="attachment_1123" align="aligncenter" width="320"] (图3:双目匹配的原理)[/caption] 就像目标检测有mAP、检准率、召回率这些指标一样,深度图同样也有一些评估的方法和指标。目前比较常用的有KITTY D1 error,它计算的是匹配失准的像素比例,以及EPE(end-to-end point error)和一些深度图定量评价指标,如平均相对误差、均方根误差、均方根对数误差、平方相对误差、精确度。 在深度图方面,主流的公开数据集有三种类型: 1)合成数据集,它先进行3D建模,然后用虚拟相机捕捉图像。优点是精度非常高,成本非常低,也能实现一些复杂的功能。缺点在于成像不真实,场景不真实。 2)激光雷达和CAD数据集,它的优势是精度和真实性高,劣势是点云稀疏,对快速移动的障碍物难以补偿,成本相对较高。 3)传统算法生成的数据集,比如用SGM或者是SFM+SGM生成,它的优势在于零成本,缺点是可靠性极差。 [caption id="attachment_1122" align="aligncenter" width="480"] (图4:不同类型数据集)[/caption] 02 不同的技术路径 在这些年的发展当中,求深度图的方法衍生出了很多不同的技术路径,既有传统方法,也有诞生于深度学习不同时期的一些方法。正是在这些技术方向的共同突破,让深度图应用到量产自动驾驶方案上成为可能。 传统方法 传统方法的性能一般,但是当中一些具有代表性的经典算法,提供了很多有价值的思路。以SGM为例,它求深度图的过程可以分为匹配代价计算,代价聚合,视差计算和视差优化,这一经典思路和其中的不少细节为之后的很多算法所借鉴。 [caption id="attachment_1121" align="aligncenter" width="640"] (图5:SGM算法示意)[/caption] 传统方法的不足之处在于,面对弱纹理、重复纹理、明暗失调、遮挡等情况时会出现难以匹配的问题。因此它的效果并不理想,求得的深度图通常连续性差,或者轮廓不清晰,甚至是存在明显的深度错误。在一些环境和场景可控的工业领域传统方法尚且适用,但是对于场景繁多的自动驾驶感知环境而言,传统方法非常具有局限性,难以胜任。 早期深度学习方法 相比之下,早期的深度学习方法在性能上就要好上不少。早期深度学习方法是在传统方法基础上做了一步改进,那就是在匹配代价计算中不再用传统的手工提取特征方法进行计算,而是改用深度学习。 早期深度学习方法的特点是,性能不错但耗时较长。在2015年,像MC-CNN这样的卷积神经网络的KITTI 2015 D1 Error已经可以达到3.6%,而传统的SGM算法是10%左右。在运行时间几乎普遍以分钟计的早期,MC-CNN的运行时间也是略多于1分钟。 [caption id="attachment_1120" align="aligncenter" width="640"] (图6:MC-CNN示意)[/caption] 值得一提的是,MC-CNN在高峰期时的变体非常多,主要的思路包括有提升网络性能,增加感受野,处理多尺度特征,简化训练过程,等等。 早期深度学习方法的思路是先用深度学习的方法求两点的相似度,然后构建3D的匹配代价体,余下部分全是传统方法去做,所以耗时很高。 当前深度学习方法 在2017年一些研究出来之后,基于深度学习求深度图的方法也到了一个新的阶段,端到端方法开始成为当前的主流。 深度学习端到端方法分为重型和轻型两条技术路径,而GC-Net是典型的重型路径。它先用2D卷提取特征,然后组建4D的代价体,全程进行3D的卷积,最后用Soft ArgMax函数求出模型的损失。 GC-Net的性能非常出色,D1-all指标达到了惊人的2.87%(对比之下MC-CNN是3.89%),而且耗时为0.9秒。不过,这类重型网络的嵌入式部署的难度很大,即使相比于早期深度学习方法已经很轻,但运行时间仍达几百毫秒。 相比之下,轻型网络的耗时很短,而且性能较可靠,最为接近量产部署。以DispNetC为例,它是DispNet的两种网络结构中稍复杂的一种,虽然它4.34%的D1-error略高于MC-CNN,但是耗时只为惊人的60毫秒。并且从一些试验结果来看,DispNet的泛化性理论上也较为不错。 深度学习方法可以比较好地处理遮挡,这也是与SGM等传统方法不同的一个地方。因为深度学习虽然学的是匹配,但或多或少还学了很多新的先验信息以及全局语义的理解。 结合时序信息的深度学习方法 这是深度学习方法求深度图的另一个独特技术分支,从2016年后开始出现,采用无监督或者是自监督的方式。 其中极具代表性的是MonoDepth2,它是一个单目深度估计的网络,利用SLAM方面的假设,将具有前后关系的图像输进网络,求得深度和相机位姿,并用t+1帧去监督t帧,将t帧推测生成的t+1帧图像与真值进行对比。 Monedepth2性能稳定,有较为不错的单目无监督的深度推理效果,但也存在一些问题,比如无法有效应对遮挡、移动目标以及非理想反射情况,而且单目推理没有求匹配关系,遇到未见过的场景会比较危险。 [caption id="attachment_1119" align="aligncenter" width="640"] (图7:无监督方式求得的深度、深度变化、光流)[/caption] 除了深度和相机位姿以外,这类方法也可以无监督地学习光流,比如GeoNet。而且求光流的方法与求深度的方法几乎完全相同,在匹配的时候用光度差值判断匹配正确与否,匹配上就能算出光流。 GeoNet在学习动态障碍物光流的过程中,可以将移动障碍物解耦出来,而且根据一些先验信息,可以直接求图像的深度,因此这个思路也相对来说有量产价值一些。 03 深度估计的主要模块 在早期的深度学习方法中,求深度图通常包括特征提取、形成代价体、代价体过滤和损失函数这几个模块。虽然当前的深度学习方法,大多属于端到端的方式,整体环节会少一些,但是也可以从中找到很多借鉴。 [caption id="attachment_1118" align="aligncenter" width="640"] (图8:经典的GC-Net的网络结构图)[/caption] 特征提取,分为基于孪生网络和基于串联(concact)的方法。孪生网络的话,左右图分别经过一个骨干网络,然后输出左右图的feature map,最后由这两个feature map组成3D或4D的代价体,这是大部分双目匹配网络使用的方法。而concat的方法在开始就将2幅图像合成6通道,全程不用孪生网络而是仅仅使用类似于分割模型的encode-decode结构,比如DispNet。 其中形成代价体也有几种方法,一种就是基于相关性的,计算两个特征向量之间的距离;另一种是基于concact的,即将左图特征直接基于视差值进行移动后与对应的右图特征进行拼接(concact),然后形成4D代价体。 在代价体过滤部分,4D代价体一般进行3D的卷积,但也可以用一些3D卷积配合2D卷积,3D代价体的话一般是2D的卷积。通常来说,4D代价体的准确性更佳,但计算量也更大。 损失函数是比较核心的部分,分为无监督和有监督两类。无监督方法包括有光度损失、视差平滑度损失、左右一致性校验损失等,有监督的则包括有L1和Smooth…05 2020/11Blog
-
能driving,能parking,TDA4的一「芯」二用了解过自动驾驶的人都知道,自动驾驶功能的实现离不开强大的计算平台,而一款强大的计算平台需要满足的要求也是出了名的“多且严格”。 计算平台不仅需要导入大量的来自摄像头、雷达等传感器的多模态的数据,而且还要将这些数据实时进行融合和分析,提取出障碍物、车道线、当前位置等等信息,从而做出决策并对接下来的速度和轨迹等内容进行规划。因此,算力可以说是计算平台的“第一生产力”。 除此之外,真正量产的自动驾驶硬件还必须在功耗、稳定性、成本等方面达到要求,确保符合车规级标准。不然的话,在天南海北的路途中和漫长的使用周期内,汽车很可能会出现各种稀奇古怪的问题。比如像一些消费电子产品一样,天冷开不了机,天热自动关机。 因此自动驾驶的计算平台需要在这些要求之间做出平衡,在确保当中不会出现“不及格”的情况下,来提高算力。 这也意味着,自动驾驶对计算平台的使用并不是随心所欲,而是要量入为出和量体裁衣。 计算平台“嵌入”之道 正是因为这些“多且严格”的要求,在自动驾驶功能量产的时候,嵌入式的计算平台是所有开发者的必然选择。 相比于通用型计算机,嵌入式计算平台具有可用性高和安全性高的特点,并且功耗低、体积小,易于集成,成本更低。而且嵌入式计算平台目前可以提供的算力,能较好满足智能化辅助驾驶或限定条件下自动驾驶的算力需求。 因此,行业内已经推出有多款车规级的嵌入式计算平台,可以不同程度地满足自动驾驶开发者在算力、可靠性、成本等方面的要求。而由德州仪器(TI)推出的TDA系列芯片,正是业内最受欢迎的计算平台之一。 TDA4是该系列中TI会于近期量产的一款芯片,主打高级别自动驾驶市场。这款面向新一代智能驾驶应用所推出的TDA4系列芯片,在性能和功耗方面都有较大提升,可以提供8TOPS甚至是更高的深度学习性能。它配有包括Cortex A72、Cortex R5F、DSP、MMA等在内的不同类型处理器,由对应的核或者加速器处理各自擅长的任务,让计算平台的效率得以提高。 相比于其他的计算平台,TDA4的突出之处就在于既有出色的性能,可以满足智能驾驶的算力需求,又有成熟的芯片设计,对功能安全考虑周到,并且在成本方面有明显优势。因此,TDA4系列芯片被众多国内外的汽车厂商和一级供应商选为基础开发平台。 那么,这是不是意味着,将各种各样的智能驾驶功能量产部署到TDA4上就是一件轻松的事呢? 打包driving和parking 事实上,在算力相对有限的车规级嵌入式计算平台上部署复杂且庞大的自动驾驶软件算法,一直以来都是件“难事”。 面对TDA4,开发者也需要“锱铢必较”地分配算力。而这也就要求开发者对于整套自动驾驶系统必须具有非常强的掌控力,甚至是在更基础的平台框架层面有深刻的理解。也正是这样,目前市场上基于TDA4的完整智能驾驶解决方案其实并不多见。 Nullmax根据TDA4系列芯片的特性对自动驾驶方案进行了定制化的开发和优化,将行车和泊车两大类型的智能驾驶功能装进了这块广受欢迎的计算平台上,让一块芯片在两种场景下派上用场。 与一些应用不同的是,Nullmax的方案为车辆提供的是完整的HWP(高速代驾)和AVP(自主泊车)功能,而不只是将某个模块或者某一项功能部署到TDA4上。虽然难度更大,但方案的“性价比”也更高。 以8TOPS算力的TDA4VM为例,如果使用6颗摄像头、5颗毫米波雷达、12颗超声波雷达,集成高精地图,将L2+的HWP和AVP整合至车辆上的方案,将比使用两套分离的系统来实现两项功能的方案,在成本上节省一大截,更具市场竞争力。 当中L2+级别的HWP,可以实现全速巡航、停走跟车、Cut-in处理、拨杆变道、横向避让,甚至是上下匝道、自主变道等功能。而在算力更充沛的TDA4VH平台上,可以接入更多传感器实现自动化程度更高的HWP,进一步丰富功能并提升安全性。 Nullmax提供的泊车功能能够进行垂直、平行和斜向车位的检测与定位,实现从地上到地下车库的最后一公里自主泊车。在TDA4平台上,Nullmax以视觉为主、融合超声波雷达的单车智能方案可以为车辆提供360°的全方位感知能力,包括低速环境下稳定的障碍物检测和测距。 尤其是在全栈自主研发的优势下和MaxOS自动驾驶平台的加持下,Nullmax的方案本身可以支持不同的车型、硬件平台和集成方式,而TDA4系列芯片的一大特点是可扩展,支持不同复杂程度的应用,因此Nullmax能够基于TDA4平台按需定制自动驾驶方案。 而且将HWP和AVP集成在一个计算平台当中,系统的架构将会更加精简,对后期的升级维护来说也将会更加方便。比如在OTA升级时,两项功能的升级可以一次完成,前后环节的重复步骤减少,效率也就更高。 当然,这些优点也不仅限于TDA4系列芯片。在其他的车规级嵌入式平台上,Nullmax的方案也同样进行了应用,在算力相对有限的情况下都能够提供完整而丰富的功能。 正如很多人所了解的一样,在自动驾驶当中,软件和硬件的搭配至关重要,既然强大的计算平台可以充分发挥出软件算法的作用,那强大的软件算法方案又会是怎样的呢? 答案是,它可以根据计算平台的特性进行开发和优化,发挥出硬件的全部性能。而Nullmax的方案,正是如此。22 2020/10Blog
-
纽劢科技与千寻位置达成战略合作,携手开拓室内外一体化高精度位置服务纽劢科技Nullmax与千寻位置网络有限公司(以下简称“千寻位置”)正式签署协议,在室内外一体化高精度位置服务领域达成战略合作。 千寻位置是全球领先的时空智能基础设施企业,凭借出色的产品技术形成了广泛的市场认可。在自动驾驶等领域,千寻位置高达动态厘米级、静态毫米级的定位能力,可为各类应用提供精准、可靠、安全的高精度定位服务,并具有全天候应用和低成本的特点,在自主泊车(AVP)等室内场景中具备优秀的定位性能。 作为国内自动驾驶量产化应用的先行者,纽劢科技自主开发了全栈的自动驾驶技术,并在视觉感知、数据融合等方面具有突出优势。所研发的独特算法和模块,借助于自研的自动驾驶平台可以进行模块化的组合应用,配置车规级硬件即可实现全场景的自动驾驶功能。 双方将基于各自的优势技术,共同开发室内外一体化位置服务解决方案。该方案将结合千寻位置的室内外高精度定位解决方案(RTK+UWB),以及纽劢科技的自动驾驶感知、规划、控制和视觉定位(VSLAM)能力,在开放场景的自主泊车、半封闭场景(例如:港口自动驾驶等场景)中进行应用。 [video width="1920" height="1080" mp4="http://en.nullmax.ai/wp-content/uploads/2022/07/2022071608293459.mp4"][/video] 融合多项技术的室内外一体化位置服务,具有全天候、全场景、高精度的技术特点,可以为自动驾驶无缝提供不同环境下的精准定位。尤其在天气恶劣、光照条件差等极端场景下,可以为AVP等应用提供安全可靠的位置依据,满足自动驾驶的量产化需求。 同时,双方也将开发相应的具备室内、室外一体化高精度定位能力的车载终端和配件,面向汽车主机厂、Tier1等客户进行推广。并在全国汽车主机厂、自动驾驶示范区等范围内,共同推广室内外一体化自动驾驶位置解决方案。 室内外一体化高精度位置服务是一个新兴领域,尤其是在自动驾驶产业的应用中具有广阔前景,全场景的精准定位能力将能为车辆安全可靠的运行提供重要保障,促进自动驾驶的大规模商用。 双方共同开发的产品方案,兼顾定位的精度、成本、应用范围、可用性等多个角度,能全面提升实际使用时的效果。多模态传感器的融合定位可以帮助自动驾驶实现精度更高、稳定性更强的定位,提升在地下停车场、城市峡谷、无场端区域等复杂场景下的应用体验。 与其它的AVP方案不同,双方研发的多源融合的方案完全基于嵌入式系统以及车规硬件,真正能够前装量产落地。 关于纽劢科技 纽劢科技Nullmax 2016年底创立于美国硅谷,总部位于中国上海,是一家专注于自动驾驶领域的科技公司,致力于应用最先进的计算机视觉、深度学习和人工智能等技术,为世界提供安全、高效、经济的自动驾驶解决方案。纽劢科技自主研发了包括感知融合、决策规划、控制在内的全栈技术,以及MaxOS自动驾驶平台,可以根据需求灵活快速地进行功能配置,基于车规级的硬件实现高速代驾、拥堵跟车、自主泊车和自动驾驶共享出行等一系列应用。 关于千寻位置 千寻位置是全球领先的时空智能基础设施公司,由阿里巴巴集团和中国兵器工业集团共同发起成立。公司成立于2015年8月,提供高达动态厘米级和静态毫米级的定位能力,是IoT时代重要的基础设施之一。千寻位置基于北斗卫星系统(兼容GPS、GLONASS、Galileo)基础定位数据,利用遍及全国的超过2500个地基增强站及自主研发的定位算法,通过互联网技术进行大数据运算,为遍布全国的用户提供精准时空服务。09 2020/06Press Release
-
劳动节 | 向每一个为AI拼搏的你致敬01 2020/05Blog
-
好消息!Nullmax登上ChinaBang Awards 2020未来出行年度榜单今天下午,由动点科技TechNode主办的ChinaBang Awards 2020线上颁奖典礼公布了新年度的未来出行年度榜单,Nullmax凭借出色的量产化解决方案登上榜单。 ChinaBang Awards 年度评选活动自2011年开始举办,旨在发掘中国各科技领域的创新力量,在历经九载的发展后已成为一项开放、独立、具有权威性的评选盛会。据悉,今年的榜单共有1000多家企业参与评选,竞逐包括未来出行在内的多个领域的榜单。 该活动从技术革新、商业模式创新、团队潜力、社会贡献价值、行业贡献价值共5个维度对企业进行评选,在经过近2个月的专家评审和大众投票后,Nullmax最终从多家提名企业中脱颖而出,入选最终的未来出行年度榜单。 作为一家专注于实现自动驾驶大规模应用的创新企业,Nullmax面向量产开发的系统化自动驾驶解决方案在行业内收到了广泛好评,在此次的评选活动中这一方案同样也给评选方留下了深刻印象。 该量产方案采用视觉为主、多传感融合感知的技术路线,技术水平行业顶尖,并且具有稳定可靠、成本优势突出等特点。方案可以提供高速代驾、拥堵跟车、自主泊车等一系列的功能,并能根据不同需求进行定制化应用。目前,该方案正在与多家车企进行量产相关的合作,有望在不久之后进入规模化应用阶段。 值得一提的是,近年来中国汽车产业的智能化趋势愈发明显,越来越多的上市车型中出现了自动驾驶的影子,众多消费者对于高速代驾、拥堵跟车、自主泊车等特色功能具有强烈的购买兴趣。在智能驾驶正成为汽车关键特点的当下,Nullmax安全、高效、经济的量产方案,可以说是极具吸引力。29 2020/04Blog
-
驾驭一辆聪明的汽车,是一种怎样的体验?和大部分人的心中所想的一样,自动驾驶的终极目标,就是汽车可以做到像人类司机一样,去往任何想去的地方。那么现在,汽车已经进化到什么程度了呢? 尽管现阶段还无法实现完全自动驾驶这样的美好理想,但是一些限定条件和场景下的自动驾驶功能,已经能够率先进入现实生活中,并且很可能出现在你即将购买的下一辆车上。 这些功能可以暂时地将你从枯燥乏味、漫长费时的驾驶中解放出来,为你在高速路上、停车场里或者是拥堵路段分担驾驶工作,甚至是在符合条件的情况下,一整段路上都能由它来自动驾驶。 没错,这就是接下来新上市的汽车技术上可以实现的功能,并且它成本经济,可以配备到普普通通的国民车型上。 对于有开车经历的朋友来说,或许都曾或多或少地体验过定速巡航、自适应巡航、车道保持、自动跟车、自动紧急刹车这些传统的ADAS功能,体会到在一些驾驶状况下这些技术所带来的帮助。 如果你接下来再试试带有这些自动驾驶功能的汽车,那么你将会体验到更加轻松惬意的驾车感受,因为无论是单一使用场景的表现还是场景间的连续可用性,自动驾驶功能的体验相比于传统的ADAS都有巨大提升。 举例来说,在传统的ADAS中,巡航功能常常只能在一定速度区间内开启,跟车功能也只能直线跟车而不能自主转弯,泊车时也只能识别部分的车位。 而在智能化程度更高的自动驾驶中,汽车能够实现0-120km/h的全速巡航,随停随走的停走跟车,处理车辆并入、横向避让车辆,也能变道超车、上下匝道,识别各种各样的车位完成停车。 匝道并入主路 应对cut-in 逆光弯道行驶 和传统的ADAS相比,自动驾驶拥有更多的传感器、更强的计算平台和更为先进完善的算法,因此它能感知到更多的环境信息,处理更加复杂的计算任务,实现更多、更复杂的功能。 这表现为,自动驾驶能够识别多种多样的物体,拥有更高的精度,具备横向控制和微距控制的能力,这些特点让自动驾驶能更加游刃有余地实现各样的功能,并且扩展出更多新的应用。 这些功能组合在一起,车辆便可以在设计的运行条件下实现长时间的自动行驶,提供非常出色的使用体验。 超车换道 驶出匝道 避障、启停 基于车规级的传感器和ECU,在不大幅增加硬件成本的情况下,车辆便可以实现这样的自动驾驶功能,为用户带来安全、连贯的用车体验。 高速代驾、拥堵跟车、自主泊车,这些非常典型的功能现在已经较为成熟,对于普通用户而言,这些功能可以说是非常的实用,因此在近几年的上市车型中很可能将会大规模地配备。 根据近两年来国内外车企更新的规划,这一点也同样非常明确,2020年开始众多车企将相继推出一些搭载自动驾驶功能的量产车型。在一些成熟的场景下,让普通消费者享受自动驾驶带来的安全、便捷。 或许这些并不是大家心中“无所不能”的完全自动驾驶,但是毫无疑问的是,在遵循法律法规和使用规范的情况下,限定条件和场景下的自动驾驶已经能够为汽车的使用带来跨越式的进阶体验。16 2020/04Blog
-
赞!Nullmax入选第三届毕马威中国汽车科技榜单国际著名会计师事务所毕马威今天正式对外发布了第三届中国汽车科技50榜单,Nullmax凭借出色的自动驾驶实力和技术特色,登上汽车科技新锐企业榜单。 (图片截取自毕马威报告) 作为全球知名的专业服务机构,毕马威对汽车出行领域的模式创新和技术创新关注多年,此前已连续发布了两届汽车科技榜单,在业内形成了广泛的影响力。 该榜单聚焦智能网联、汽车后市场服务、出行方式和汽车制造四大领域,从技术与模式创新、财务健康状况等六大维度对企业进行全面分析。在经过严格的筛选及评估过后,Nullmax最终入选了第三届汽车科技新锐企业榜。 Nullmax不仅拥有独立自主开发完整自动驾驶解决方案的全栈技术,尤其是极其出色的以视觉为主、多传感融合的感知能力,还凭借在工程化、产品化方面的深厚积累,成功将技术转化为可量产的方案。 目前,Nullmax正式推出的产品可实现高速场景的HWP、拥堵场景的TJP、泊车场景的AVP等一系列应用,这些方案均采用车规级的传感器及计算平台。无论是在功能的丰富性还是单一功能的性能上,方案相较于大多数的同类产品均具有领先优势。 这次获得专业机构的认可,再一次证明了Nullmax在技术、市场和发展潜力等多个方面出色的综合实力。作为一家出色的科技企业,Nullmax将继续聚焦技术的研发和商业化应用,推进自动驾驶方案的量产落地。21 2020/04Blog
Follow Us


For Report
You can download Nullmax's latest graphic and video materials here.
For more information and in-depth report, please contact us.
Contact us